

Build trust with every incident
Easily communicate real-time status to your users. Just like DigitalOcean, Dropbox, and Intercom.
DigitalOcean
Dropbox
Intercom
Support & IT teams
Eliminate duplicate support tickets & clunky email lists
Halt the flood of support requests during an incident with proactive customer communication. Manage subscribers directly in Statuspage and send consistent messages through the channels of your choice (email, text message, in-app message, etc.)

DEVOPS & IT TEAMS
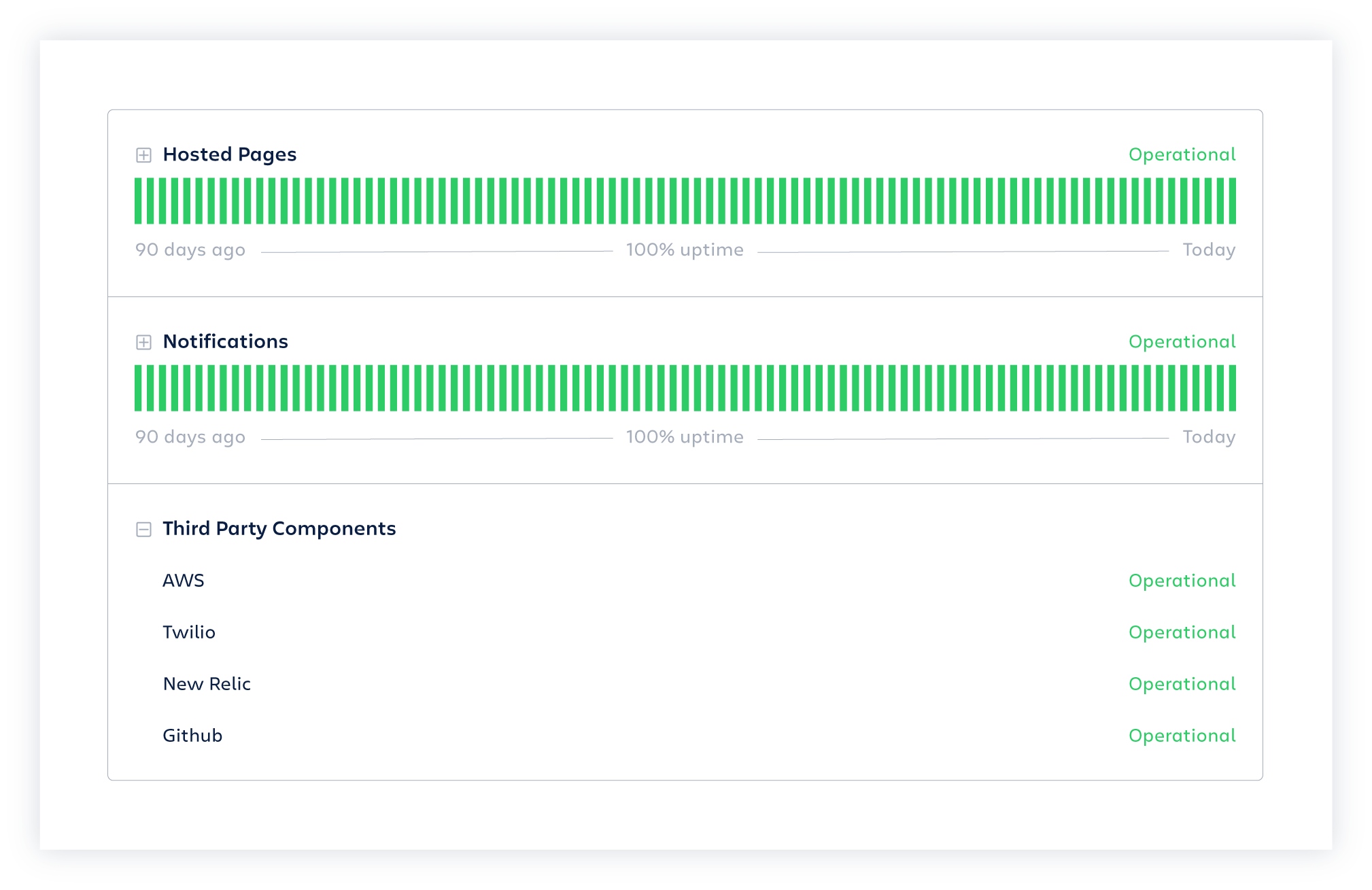
Display the status of each part of your service
Control which components of your service you show on your page, and tap into 150+ third party components to display the status of mission-critical tools your service relies on like Stripe, Mailgun, Shopify, and PagerDuty.
Statuspage is the communication piece of your incident management process
Keep users in the loop from ‘investigating’ through ‘resolved’.
Statuspage integrates with your favorite monitoring, alerting, chat, and help desk tools for efficient response every time.
INCIDENT RESPONSE TEAMS
Level-up your incident communication
Take the hassle out of incident communication. Pre-written templates and tight integrations with the incident management tools you already rely on enable you to quickly get the word out to users.

MARKETING & SALES TEAMS
Showcase reliability
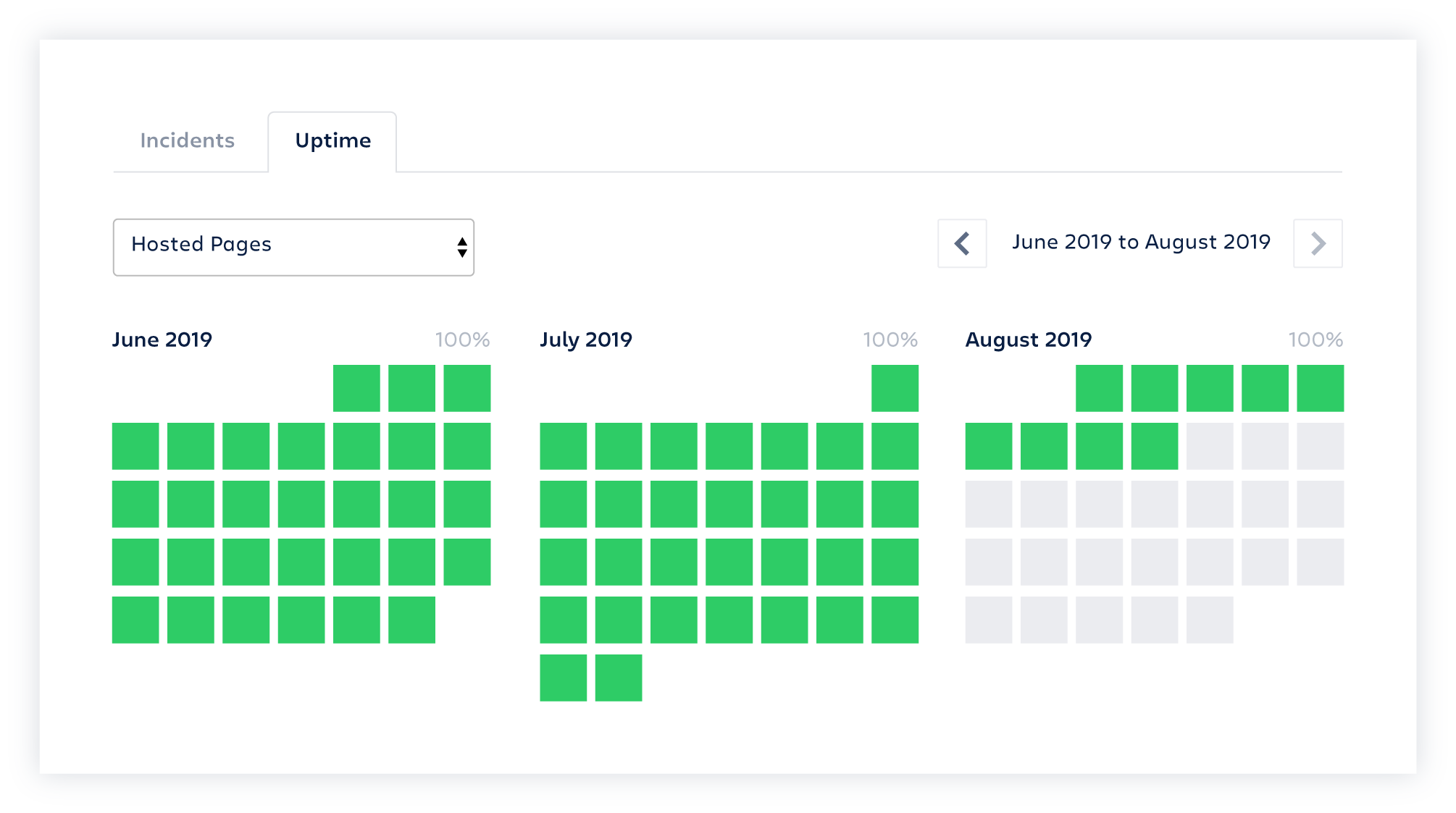
Turn your page into a sales and marketing tool with Uptime Showcase, which lets you display historical uptime to current and prospective customers.
Trusted by thousands of companies
“Proactive Statuspage notifications drive down ticket volume during an incident.”






Pricing that scales with you as you grow
No minimum contracts, no sign-up fees, no cancellation fees
Communicate publicly with your users and customers during an incident.
Hobby
-
250 subscribers
-
5 team members
-
5 metrics
-
Email notifications
-
Slack notifications
-
Microsoft Teams notifications
-
Basic customization
-
Custom domain
- Access to REST APIs
Startup
-
1,000 subscribers
-
10 team members
-
10 metrics
-
Email/SMS/webhook notifications
-
Slack notifications
-
Microsoft Teams notifications
- Custom CSS
-
Custom domain
- Access to REST APIs
- Team member SSO (with Atlassian Access)
Business
-
5,000 subscribers
-
25 team members
-
25 metrics
-
Email/SMS/webhook notifications
-
Slack notifications
-
Microsoft Teams notifications
- Custom CSS/HTML/JS
-
Custom domain
- Access to REST APIs
- Team member SSO (with Atlassian Access)
-
Component subscriptions
-
Role-based access control
Enterprise
-
25,000 subscribers
-
50 team members
-
50 metrics
-
Email/SMS/webhook notifications
-
Slack notifications
-
Microsoft Teams notifications
- Custom CSS/HTML/JS
-
Custom domain
- Access to REST APIs
- Team member SSO (with Atlassian Access)
-
Component subscriptions
-
Yearly purchase orders and invoicing available
-
Role-based access control
Communicate privately with your employees about issues with internal tools and services.
Starter
-
5 team members
-
50 authenticated subscribers
-
5 metrics
-
Email notifications
- Custom CSS
-
Incident templates
- Team member SSO (with Atlassian Access)
-
Email support
Growth
-
15 team members
-
300 authenticated subscribers
-
15 metrics
-
Email/SMS/webhook notifications
- Custom CSS/HTML/JS
-
Incident templates
-
Component subscriptions
-
IP allowlisting
- Team member SSO (with Atlassian Access)
-
Email support
Corporate
-
35 team members
-
1,000 authenticated subscribers
-
35 metrics
-
Email/SMS/webhook notifications
- Custom CSS/HTML/JS
-
Incident templates
-
Component subscriptions
-
IP allowlisting
- Team member SSO (with Atlassian Access)
-
Yearly purchase orders, and invoicing available (for eligible purchases)
-
Email support
-
Role-based access control
Enterprise
-
50 team members
-
5,000 authenticated subscribers
-
50 metrics
-
Email/SMS/webhook notifications
- Custom CSS/HTML/JS
-
Alerting integrations
-
Incident templates
-
Component subscriptions
-
IP allowlisting
- Team member SSO (with Atlassian Access)
-
Yearly purchase orders and invoicing available
-
Email support
-
Role-based access control
-
Account representative support
Different views for different sets of users

